| This project was carried out by the Natural Language Processing team of Oujda (Oujda-NLP team), from Mohammed I University in Morocco, with the support of the Arab League Educational, Cultural and Scientific Organization (ALECSO). |  |
| Download Source | Download Jar |
|
Introduction Alkhalil Diacritizer allows to recover the diacritics of the words of a given sentence taking into account their contexts. The proposed system comprises two modules. The first one consists of an analysis out of context, based on the morphosyntactic analyser Alkhalil Morpho Sys 2. In the second module, we use the word context to identify its correct diacritized form from the potential diacritized forms of the word obtained by the first module. For this purpose, we use a statistical technique based on the hidden Markov models, where the observations are the words of the sentence, and the roots represent the hidden states. We use also some syntactic rules to eliminate the wrong solutions. We validate this approach using a large corpus of more than 72 million diacritized words. The rate of the words incorrectly diacritized by Alkhalil Diacritizer is about 6%. |
|
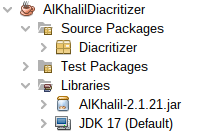
Structure of the program The program is composed from several packages as described in the Figure 1: |
|
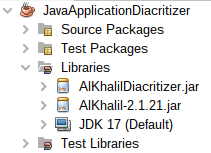
Using the API in another project To process a file, you must use Alkhalil Morpho Sys and add the jar file in the library class path (Figure 2) and use the following code to analyse a raw file: |
|
For further details, please check the following paper : |